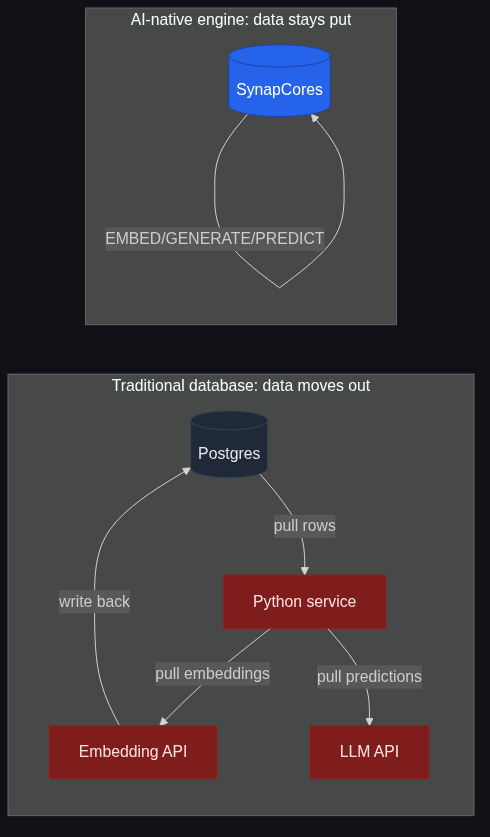
The first AI application I shipped on a "modern" stack — Postgres + pgvector + a Python ML service + Redis cache + the OpenAI API — looked clean on the architecture diagram and was a misery to operate. The data lived in five places. The latency budget was eaten by network hops. The cache invalidation problem alone took three months to stop being a weekly outage. Six months in I realized: the database wasn't failing. The role we were asking the database to play was failing. We were treating it as a passive store while every interesting computation happened somewhere else.
That's the structural problem with traditional databases in the AI era. They were designed for a world where the application asks "give me row X" and the database hands it over. AI workloads invert that contract. The interesting computation — embedding, similarity, classification, generation — needs to happen next to the data, not in a service two network hops away. Every time you move data, you pay for it in latency, money, sync bugs, and engineering hours.
This post is the case that traditional databases are structurally mismatched to modern AI workloads, what the specific failure modes are, and what an AI-native database has to do differently. The examples use SynapCores SQLv2 where syntax matters. The argument applies whether you build on SynapCores, on a custom stack, or on something else entirely.
What "traditional database" means here
I'm using "traditional database" to mean the OLTP/OLAP relational family: Postgres, MySQL, SQL Server, Oracle. These systems are excellent at what they were designed for: transactional row-and-column storage, joins, indexes, ACID guarantees. They've earned their thirty-plus years of dominance.
What they were not designed for: storing 768-dimensional vectors, running similarity search at scale, calling language models from inside a query, training ML models on table contents without copying the data out. Extensions like pgvector graft some of this on, and they work — but the architectural assumption that the database is a passive store leaks through everywhere.
The five failure modes
Here's the list I've kept from production debugging. Every team running serious AI on a traditional stack hits at least three of these.
1. Data gravity tax
ML workloads are heavy. A million rows of customer transactions is small for a database; a million rows passed through an embedding model is a real workload that needs GPU minutes. The traditional pattern moves the million rows out of the database, through the network, into a Python service, out through another network, into an ML service, and the results back into the database. Every hop is bandwidth, serialization, latency.
A real number from a project last year: the embedding step in a customer-support pipeline cost about 40% of the total request latency just in data movement — pulling the text out of Postgres, JSON-serializing it, shipping it to the embedding service, deserializing the result, writing it back. The actual model inference was 60ms. The data movement around it was 90ms.
When the AI lives next to the data, that 90ms goes to zero. That's the data gravity argument: data is heavy, computation is light, move the light thing to where the heavy thing already is.
2. The synchronization tax
Every AI app I've seen on a traditional stack has the same shape: a primary database, a vector index, a cache, a feature store, and a Python orchestration layer. Each store has its own copy of (some subset of) the data. Each copy has to be kept in sync. Each sync job is a place where bugs live.
The canonical version: a row is updated in Postgres. The embedding in Pinecone is now stale. The cache in Redis still has the old result. The feature store recomputes nightly and won't pick this up until tomorrow. Three out of four services are now lying about the world. The vector search returns the right cosine match to the wrong text. Welcome to "RAG hallucination" that isn't actually the LLM hallucinating — it's retrieval returning stale data because four indexes disagree.
This isn't unsolvable. It's just expensive. Every AI team I know has spent at least one engineer-quarter on cross-store consistency that they would not have spent if the AI primitives lived inside the same engine as the data.
3. The query language is wrong
SQL was designed in 1974 to express set-oriented data manipulation. It has no native concept of "the embedding of this column," "find the K most similar rows," "ask a language model to summarize this group," or "predict this column from those columns." When you graft these onto SQL via extensions, the syntax fights you.
Compare:
-- Postgres + pgvector + external LLM API call (pseudocode for the LLM bit)
WITH question_emb AS (
SELECT embed_via_external_api('what is our refund policy?') AS v
)
SELECT t.body
FROM tickets t, question_emb q
WHERE t.embedding <-> q.v < 0.4
ORDER BY t.embedding <-> q.v
LIMIT 5;
-- now ship the 5 rows to a Python service to call the LLM and synthesize
vs
-- SynapCores SQLv2
SELECT GENERATE(
'Answer this using only the following tickets: ' || STRING_AGG(body, ' | '),
'gpt-4o-mini'
) AS answer
FROM tickets
WHERE COSINE_SIMILARITY(embedding, EMBED('what is our refund policy?')) > 0.6
ORDER BY similarity DESC
LIMIT 5;
The second version doesn't just have nicer syntax — it has one execution context. There's no Python service in the loop. The optimizer can fuse the vector lookup and the LLM call. The whole thing runs in one process, one transaction, one round-trip.
What Is SQLv2? goes deeper on the SQL extensions that make this work.
4. The feature-store antipattern
Most ML teams running on traditional databases end up building a "feature store" — a secondary system that pre-computes features from the database and serves them to the ML model. The feature store exists because the database can't do the feature computation natively. It's a workaround that has become so common it's marketed as best practice.
I'm not going to claim feature stores are evil. I'm going to claim they're a tax. Every feature has to be defined twice: once in SQL for the database, once again in the feature store's DSL. Every feature has to be kept in sync. Every backfill is a coordinated dance between two systems. The team that doesn't have a feature store is usually a team whose database can compute features natively — at which point they don't need one.
If your database can run EMBED(), PREDICT(), GENERATE() as first-class SQL functions, you don't have a feature-store-shaped hole in your architecture. The features are just columns.
5. The MLOps hairball
Pull data out → train model → ship model artifact → deploy to inference service → wire inference service into the application → monitor → retrain. Each step is a different team, a different tool, a different deployment, a different on-call rotation. This is the MLOps pipeline that ate the AI industry.
The structural cause is the same as the other failure modes: ML lives outside the database, so the database can't participate in the lifecycle. Every artifact has to be marshalled between systems. When training data changes, the database doesn't know. When the model improves, the database doesn't know. The two halves of the stack are blind to each other.
An AI-native engine can train, version, and serve models from inside the database. The model artifact is just a row. Retraining is a query. Inference is PREDICT(...). Monitoring is SELECT COUNT(*) FROM predictions WHERE confidence < 0.5. This isn't easier because the AI got easier — it's easier because the artifacts and the data finally live in the same place.
What the architecture has to do differently
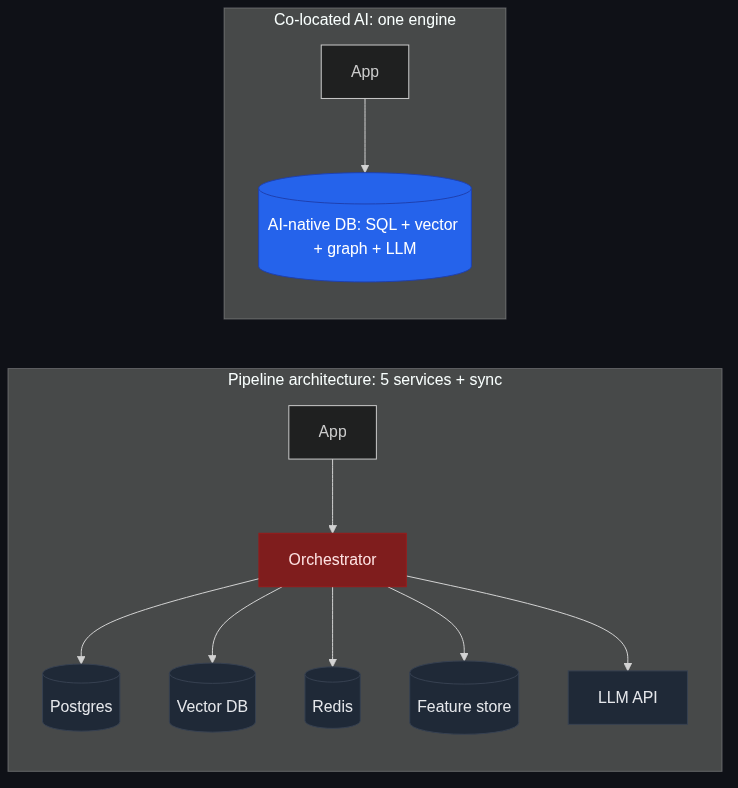
An AI-native database doesn't have to be novel. It has to make four specific design choices:
- Vectors are first-class types. Not an extension. Not a column type that pretends to be JSON. A real
VECTOR(n)type that the planner understands. - Embedding, generation, and prediction are first-class functions.
EMBED(),GENERATE(),PREDICT()callable from SQL with no Python in the loop. - The graph engine and the SQL engine share storage. Cypher walks the same B-tree the SQL planner walks. No sync, no ETL.
- Model artifacts are rows. Training is a query. Inference is a function. The lifecycle lives in the database, not in a sidecar.
That's it. Not magic, not revolutionary — just admitting that AI workloads have different operational shapes than 1990s OLTP and designing accordingly.
The pgvector counter-argument
The honest objection: "pgvector exists. Postgres has vectors now. Why do I need a new database?"
Two answers. First: pgvector solves one of the five failure modes above (vectors as types) and doesn't address the other four. You still don't have GENERATE() or PREDICT() in SQL. You still need an external orchestrator. You still have the sync tax once you add a graph store. It's a real improvement and it's still a stack, not an engine.
Second: pgvector is the right answer when you already have Postgres in production and adding vector search is the only AI capability you need. If you're building a recommendation system on top of an existing app, pgvector is plausibly the lowest-effort path. The longer comparison is in our SynapCores vs pgvector post.
But: if you're building a new AI-heavy application from scratch, defaulting to "Postgres + pgvector + Python service + LangChain" because that's the familiar stack means signing up for the five failure modes above and discovering them one by one over the next eighteen months. I know because I've watched several teams do it.
A rule of thumb for picking
Don't switch databases for fun. Here's the cheap heuristic I use when teams ask:
- Less than ~30% of your application's compute is AI work? Stay on your traditional database. Add pgvector or a sidecar vector index. The data-movement tax is real but bounded.
- More than ~30% of your application's compute is AI work? Seriously evaluate an AI-native engine. The five failure modes compound fast above that threshold.
- Building a net-new AI-heavy product? Default to AI-native. The greenfield case is the easiest case for switching — no migration, no existing investment.
The point isn't "always replace your database." The point is that the database-as-passive-store pattern doesn't survive contact with AI-heavy workloads.
For the contrast on what the alternative looks like in practice, see What Is In-Database Machine Learning?.
What I'd do today
If I were starting a new AI product tomorrow and had to pick a data layer, I'd evaluate three options against the five failure modes above:
- Traditional DB + extensions + orchestrator. Lowest novelty, highest long-term tax. Right answer if AI is <30% of your workload.
- Best-of-breed stack (Pinecone + Neo4j + Postgres + LangChain). Each piece is excellent in isolation. The seams will eat you.
- Unified AI-native engine. SynapCores is one such option. There are others — but the category is what matters, not the brand. The win is removing the seams.
Score each on data-movement cost, sync surface area, query-language fit, feature pipeline complexity, MLOps overhead. The right pick is the one whose total cost over 24 months is lowest, not the one with the cleanest day-one architecture diagram.
The honest version
We don't have customer logos yet. We built SynapCores because we hit all five failure modes on a previous product and got tired of the seams. If you're hitting any of them — the data-gravity tax, the sync tax, the wrong query language, the feature-store tax, the MLOps hairball — that's the pain point the Agent Memory JumpStart is designed to relieve. Two to four weeks, founder-led, free Design Partner or fixed-fee Paid Pilot from $5,000.
Or download the Community Edition and just write SELECT GENERATE(...) in SQL once. That's the demo.