
I have a half-broken RAG pipeline in my notes folder from late 2024. It was a customer-support copilot, and on a good day it answered 80% of questions correctly. On the bad days — and there were many — it would confidently cite three chunks that were tangentially related to the question and ignore the one chunk that actually answered it. The chunks were all on-topic by cosine similarity. The problem was that the right answer required combining two chunks that lived under different documents, and the embedding model had no way to know they were related.
That's the gap GraphRAG fills. Traditional RAG asks "what chunks look like this question?" GraphRAG asks "what chunks look like this question, and what are they connected to?" The second question is harder to answer, but for a large class of real-world questions it's the only one that produces an actual answer.
This post is a side-by-side: how each architecture works, where they diverge, what they cost, and how to decide which one to build. I'll use SynapCores SQLv2 for examples because both shapes compile in one engine and the syntax is small enough to fit in a blog post — but the analysis applies regardless of stack.
What "traditional RAG" actually is
The phrase "traditional RAG" is doing a lot of work, so let's pin it down. By traditional RAG I mean the canonical retrieval-augmented-generation pattern published in the original 2020 Lewis et al. paper and popularized by LangChain, LlamaIndex, and every "build a chatbot over your PDFs" tutorial since:
- Chunk the corpus into ~500-token windows.
- Embed each chunk with a sentence-transformer.
- Store embeddings in a vector index (Pinecone, Chroma, FAISS, pgvector, etc.).
- At query time: embed the question, fetch top-k by cosine similarity, paste into the prompt.
- Let the LLM synthesize.
That's it. There is no model of what the chunks are, who they belong to, or how they relate. The corpus is a flat bag of strings indexed by meaning. This is the right baseline. It works astonishingly well for a lot of questions. It also has well-documented failure modes that the GraphRAG literature is a response to.
What GraphRAG adds
GraphRAG keeps the vector index and adds a graph. Specifically:
- Entities extracted from the chunks (people, companies, products, topics, tickets, accounts — whatever your domain has).
- Edges between those entities, typed by relationship (
MENTIONS,WORKS_AT,RESOLVED_BY,CONTRADICTS). - Retrieval expansion that, after fetching the top-k chunks, walks the graph N hops out to find connected context.
The retrieval result is no longer a flat list of chunks. It's a subgraph: chunks, their associated entities, and the edges between them. The LLM gets handed structure, not just text.
If you want the longer architectural treatment of what GraphRAG is, read the primer — this post focuses on the comparison.
The four failure modes traditional RAG can't fix
I've kept a running list. In rough order of how often I see them in production:
1. Multi-hop synthesis
Traditional RAG can return chunks A and B that each contain part of an answer, but it can't tell the LLM that A and B are connected. If chunk A says "Account 42 is in Org 7" and chunk B says "Org 7 had a billing incident in March," the LLM has to guess that the link between them is what makes the answer.
GraphRAG returns the edge Account 42 → BELONGS_TO → Org 7 with both chunks, so the synthesis is explicit.
2. Entity disambiguation
"Did the user reset their password?" Whose password? Vector search gets fuzzy here because "password reset" matches a thousand chunks. With a graph, you can scope the retrieval: MATCH (u:User {id: $session_user})-[:REQUESTED]->(t:Ticket {topic: 'password'}). The vector search is bounded by the graph structure.
3. Temporal reasoning
When did this stop being true? Traditional RAG embeds the text of a fact, not its validity window. GraphRAG can attach valid_from and valid_to to the edge, so retrieval naturally filters out obsolete claims.
4. Path citations
The product question "why did the model say that?" is much easier to answer when retrieval returns a literal path. Citing "chunk #4837" is fine. Citing "Account 42 → BELONGS_TO → Org 7 → HAD_INCIDENT → Incident 19 → DESCRIBED_BY → chunk #4837" is a real audit trail.
Side by side: same question, both architectures
Let's use a concrete example. The question: "What past tickets in the same parent org have touched MRI integration on the Pro plan?"
Traditional RAG path
-- One vector lookup. That's the entire retrieval.
SELECT id, body
FROM tickets
WHERE COSINE_SIMILARITY(embedding, EMBED('MRI integration Pro plan past tickets'))
> 0.6
ORDER BY similarity DESC
LIMIT 10;
What you get: ten chunks whose text looks like the question. Some are from the right org. Some are from totally unrelated customers. Some are from the right org but were resolved years ago when the integration was completely different. The LLM has to figure out from text alone which apply.
GraphRAG path
-- Vector seed + graph expansion in one statement
WITH seeds AS (
SELECT id, account_id
FROM tickets
WHERE COSINE_SIMILARITY(embedding, EMBED('MRI integration Pro plan'))
> 0.6
ORDER BY similarity DESC
LIMIT 5
)
SELECT t.id AS ticket_id,
t.body AS ticket,
a.id AS account,
a.plan_tier AS plan,
o.id AS org,
r.body AS resolution
FROM seeds s
GRAPH MATCH
(Ticket {id: s.id})-[:FILED_BY]->(:Account {id: s.account_id})
-[:BELONGS_TO]->(o:Org)
<-[:BELONGS_TO]-(a:Account)
<-[:FILED_BY]-(t:Ticket)
-[:HAS_RESOLUTION]->(r:Resolution)
WHERE a.plan_tier = 'Pro'
ORDER BY t.created_at DESC
LIMIT 5;
What you get: the seed chunks, plus the parent-org tickets, plus the resolutions for those tickets, plus the plan tier of the accounts that filed them. The LLM doesn't have to guess what's connected — the edges are in the response.
Where each architecture wins
I want to be careful here because GraphRAG gets oversold, and traditional RAG gets undersold. The honest comparison:
| Dimension | Traditional RAG | GraphRAG |
|---|---|---|
| Time to first answer | Minutes (chunk + embed + query) | Hours-to-days (entity extraction + schema design) |
| Operational complexity | One index | Vector index + graph + sync (unless you have a unified engine) |
| Question shape it answers well | "What does the corpus say about X?" | "How is X connected to Y, and what evidence supports it?" |
| Citation quality | Per-chunk citations | Path-of-evidence citations |
| Hallucination resistance | Medium (depends on chunk quality) | Higher when relations matter; same as vector when they don't |
| Cost per query | One vector lookup | Vector + graph traversal (typically 1.5-3x latency) |
| Build cost (engineering hours) | Days | Weeks (schema + extraction + eval) |
| Debugging | "Which chunk?" | "Which path?" |
The biggest hidden cost of GraphRAG is schema design. A good graph schema is the difference between a useful GraphRAG system and an overengineered toy. You need to decide what an entity is (and isn't), what relationships matter, and how to extract them. This is usually two-to-four weeks of work and it's the part most teams underestimate.
When traditional RAG is the right answer
Don't reach for GraphRAG when you don't need it. Traditional RAG is the better choice when:
- The corpus is genuinely flat (FAQ documents, product descriptions, news articles you treat as standalone).
- The questions are single-chunk ("what's the refund policy?", "summarize this PDF").
- You don't have time or expertise to design a graph schema.
- Latency budget is tight and you can't afford the extra hop.
A specific failure I've seen: a team built a "knowledge graph" with one edge type — HAS_CHUNK — and called it GraphRAG. It performed worse than their previous vector-only system because the graph added latency without adding signal. If your graph has no real edges, it's not a graph.
When GraphRAG is the right answer
Reach for GraphRAG when the question shape is relational:
- "What other accounts have had this issue?" (org graph)
- "Who else cited this paper?" (citation graph)
- "Which devices share this card with the flagged account?" (fraud-ring graph)
- "What's the chain of approvals on this PR?" (workflow graph)
- "What past resolutions apply to this customer's parent org?" (support graph)
In each of these, the answer literally is a path. Traditional RAG can sometimes stumble onto the right chunks, but it has no way to express the path it took — which means it can't reliably reproduce the answer, can't cite it cleanly, and can't filter on relationship properties.
The architecture cost: keeping two stores in sync
If you build GraphRAG on a vector DB plus a separate graph DB, you've signed up for an ETL job between them. Every entity write goes to two stores. Every retrieval is a fan-out. Every debugging session starts with "which side is stale?"
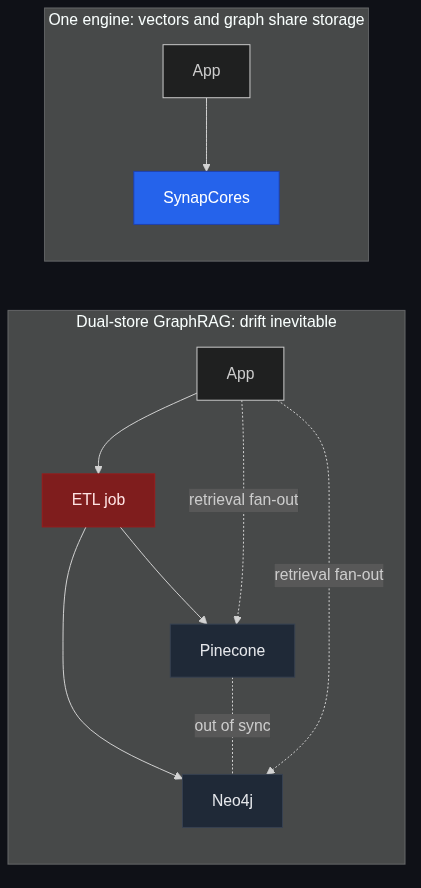
This is solvable with discipline, but it's a real cost. Pinecone + Neo4j + the LangChain glue is a four-piece dependency tree that ships behind your application. Every upgrade is a coordinated upgrade. Every outage in any of the four breaks retrieval.
We built SynapCores' GraphRAG path as one engine specifically because we got tired of paying this tax on every project. The agentic memory system post goes deeper on the dual-store sync problem if that's the angle you want.
A latency rule of thumb
We've benchmarked GraphRAG vs vector-only on the same hardware with the same data. The honest rough number: GraphRAG adds 30-150% latency depending on graph depth and result size. A 50ms vector-only query becomes 80-130ms with a 2-hop graph expansion.
That's not nothing. But for the question shapes GraphRAG is good at, the answer quality delta typically dwarfs the latency delta. A 130ms answer that's right beats a 50ms answer that's wrong.
If latency is your bottleneck and you don't need multi-hop reasoning, stay on vector. If answer quality on relational questions is your bottleneck, GraphRAG pays back the latency many times over.
How to decide
I run through this mental checklist when someone asks "should we use GraphRAG?":
- Does your data have real entities and real relationships? If no → traditional RAG. If yes → continue.
- Do your questions actually require relationship reasoning? Run a sample of 50 real user questions and label each "single chunk would suffice" vs "needs multi-hop". If more than ~20% are multi-hop, GraphRAG is probably worth it.
- Do you have the team to design and maintain a graph schema? This is the make-or-break.
- Is the latency budget compatible with a 30-150% increase? Usually yes for assistants and search; usually no for autocomplete.
If all four point to yes, GraphRAG is the right move. If any point to no, traditional RAG is the right move — and you can revisit later when the failure modes start hurting.
For more on the upgrade path from vector to graph-aware retrieval, see Why Vector Search Needs Graph Relationships and Why Vector Search Alone Fails Complex Reasoning.
The honest version
We don't have customer logos yet. The two-store sync pain is what made us build a unified engine instead. If you want to skip the schema-design grind and the four-service stack, the Agent Memory JumpStart is a 2-4 week founder-led sprint where we wire SynapCores' GraphRAG into your real workflow — design partner track is free in exchange for feedback, paid pilot is fixed-fee from $5,000.
Or grab the Community Edition and run recipe 016_graphrag_qna on your own data. If it doesn't fit your shape, tell me what broke and we'll figure out whether GraphRAG is the right answer for you in the first place.