I spent most of 2024 convinced that the answer to "how do we make our agent smarter?" was "better embeddings." We tuned models. We chunked at different granularities. We added re-rankers. We bought into the "all you need is vector search and a good LLM" narrative. The agent got better at finding similar things and no better at reasoning across things. By Q4 I was looking at our eval set and realizing that the questions our agent couldn't answer all had the same shape: they required following relationships, not finding lookalikes.
That observation is the entire argument for adding a graph to your retrieval path. Vector search is excellent at one thing — finding semantically similar items — and is structurally incapable of doing the other thing complex reasoning requires: traversing typed relationships between items. No amount of embedding tuning closes that gap, because the gap isn't about meaning. It's about structure.
This post is about why that gap exists, what kinds of questions reveal it, and what to do about it. The examples use SynapCores SQLv2, but the conclusion is independent of stack.
What vector search actually does
A vector index — HNSW, IVF, or any other — answers exactly one question: given this query vector, find the K vectors closest to it under this distance metric. That's it. It does this fast (sub-100ms at million-scale) and it does it well. The geometry is honest: similar things end up near each other in embedding space because the embedding model was trained to put them there.
The trouble starts when you assume that "nearness in embedding space" maps to "answers my question." Sometimes it does. Often it doesn't.
For a deeper dive into how the index itself works, see HNSW Explained. For now, the relevant point is: a vector index is a proximity oracle. It has no concept of edges, no concept of types, no concept of paths.
The four question shapes vector search can't answer
I've kept a running list from real production debugging. These are the shapes where vector-only retrieval reliably fails:
1. "What is connected to X?"
Examples: "Which accounts share devices with this flagged user?" "Which papers cite this one?" "Which tickets in the same parent org touched this integration?"
Vector search can find the seed (X itself) but has no way to walk outward from it. You can try to embed the question in a way that drags in connected entities, but the embedding model doesn't know your domain's edges. It only knows what the corpus said.
2. "What is the path from X to Y?"
Examples: "How is this customer connected to that other customer through our org graph?" "What chain of approvals led to this PR being merged?" "What's the dependency path between these two services?"
Vector search has no notion of "path." Even if it returns both endpoints, it can't return what's between them. The whole concept of intermediate nodes is foreign to the index.
3. "What was true at time T?"
Examples: "What did our pricing page say last March?" "What was the plan tier of this account when the incident happened?"
Vector search embeds the current text. It has no temporal model. You can store multiple versions and filter by timestamp, but you're outside the vector index doing that — and you've now lost the ranking signal that made vector search useful in the first place.
4. "Why?"
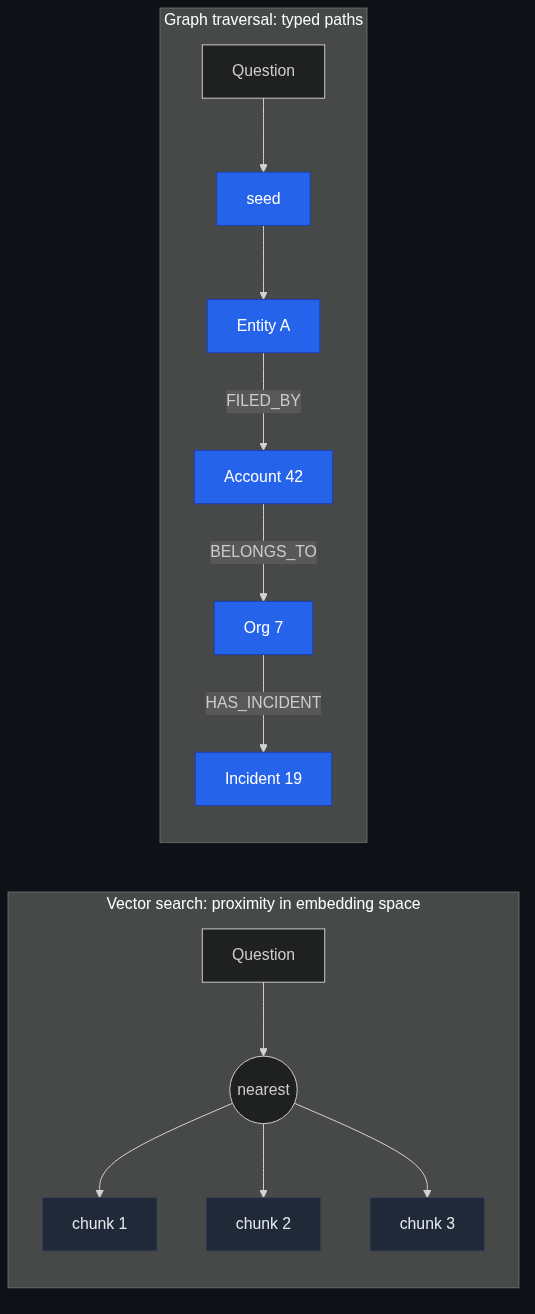
This is the one that hurts most. The product question "why did the agent say that?" is essentially unanswerable when retrieval returns a flat list of chunks. "Because chunks 4837, 5012, and 6219 had cosine similarity above 0.7" is not a why. A graph-aware retrieval can return "because Account 42 → BELONGS_TO → Org 7 → HAD_INCIDENT → Incident 19 → DESCRIBED_BY → chunk 4837," which is an actual chain of reasoning.
A concrete failure: the support copilot that couldn't escalate
Here's a real shape I debugged. A support copilot was supposed to flag tickets that matched known fraud patterns. The fraud pattern was structural: a fraud ring shares devices, IPs, or payment cards across multiple accounts. The team's first attempt used vector search over ticket bodies plus device fingerprints.
It almost worked. It would surface tickets with similar fraud-y language, and it would surface tickets that shared a single device. What it couldn't do was answer the real question: "which clusters of accounts share devices, IPs, AND cards?" That requires multi-hop graph traversal:
MATCH (a1:Account)-[:USED]->(d:Device)<-[:USED]-(a2:Account)
MATCH (a1)-[:PAID_WITH]->(c:Card)<-[:PAID_WITH]-(a2)
WHERE a1.id <> a2.id
RETURN a1, a2, d, c
Vector search could not express that question. Not "could not express it well" — could not express it at all. The shape of the question is structural, and structural questions need structural retrieval.
The fix wasn't a better embedding model. The fix was adding a graph layer. After that the false-positive rate dropped substantially because the system finally had a way to encode "shares both device AND card" as a single concept.
The "but I can just embed the relationships" objection
Every six months someone suggests embedding the relationships into the chunk text — "Account 42 belongs to Org 7" as a sentence in the corpus — so that vector search can find it. I tried this for an embarrassingly long time. It doesn't work for three reasons:
-
The combinatorial explosion is brutal. Every node-edge-node triple is its own sentence. A modest graph with 100k nodes and 1M edges becomes 1M sentences in the corpus. You're now embedding and storing a graph as text, badly.
-
The embedding model doesn't know the schema. Two sentences "Account 42 belongs to Org 7" and "Account 42 reports to Org 7" might embed nearly identically. The graph would never confuse
BELONGS_TOwithREPORTS_TO. Your retrieval just lost type information. -
You can't walk it. Even if you successfully retrieve "Account 42 belongs to Org 7," you can't follow the edge from Org 7 to another account in one query. You'd have to do a second vector search, then a third, then a fourth. That's traversal-as-RPC, and it's slow, lossy, and a maintenance burden.
A graph is the right data structure for relationships. Trying to flatten it into text and re-discover it via vector similarity is the equivalent of storing a B-tree as a sorted CSV and re-discovering O(log n) lookups by linear scan.
What graph traversal adds, in one diagram

Vector search returns a set. Graph traversal returns a subgraph. The cardinality difference matters: a subgraph is a strictly richer structure than a set, and the LLM in the synthesis step can exploit that richness.
When I think about this geometrically: vector search is a ball in embedding space, graph traversal is a tree-walk in relationship space. They answer different questions because they operate in different spaces. Combining them is GraphRAG. Replacing one with the other is a category error.
The honest case for keeping vector search
I want to be careful not to dunk on vector search. It's still the right primitive for an enormous class of problems:
- "Find the chunk that answers this factual question." Single-chunk RAG works fine for this.
- "Find similar items." Recommendations, dedup, near-duplicate detection.
- "Find the seed for further analysis." Vector search is great for the first hop of a GraphRAG pipeline.
The argument isn't that vector search is bad. The argument is that vector search is necessary but not sufficient for retrieval that supports complex reasoning. You need both: the vector index to find the right starting points, the graph to walk outward from those starting points.
How to recognize vector-only failure modes in your eval set
Concrete tactic: take a sample of 50 user questions from your real product. Manually answer each one yourself, paying attention to the steps you took. For each step, ask "did I just find a chunk by meaning, or did I follow a relationship?"
If more than ~20% of your reasoning steps involve following a relationship, your eval set is telling you to add a graph. If less than 5% involve relationships, you're probably fine with vector-only and a re-ranker.
This sounds simple but it's the single most informative exercise I run when a team asks me "should we add a graph?" Don't argue from architecture. Look at what your users actually ask and what answering those questions actually requires.
Adding a graph without adding a database
The "well, do we have to deploy Neo4j now?" reaction is the most common pushback. It doesn't have to be that. Three options, in increasing order of how much I like them:
- Bolt a graph DB onto your stack. Neo4j, Memgraph, JanusGraph. Works, but adds operational surface and a sync problem with the vector store.
- Use a multi-model database that supports both. ArangoDB, OrientDB. Better, but you still write to two indexes and the ecosystem is smaller.
- Use an engine where vector and graph share the storage layer. This is what SynapCores does — Cypher and vector operators are first-class in the same SQL planner, so a query can seed by vector and expand by graph in one round-trip.
The point isn't that option 3 is the only way. The point is that adding a graph doesn't require five extra services. Pick whichever option matches your team's appetite for operational complexity.
For the longer comparison with the standalone graph DB approach, see GraphRAG vs Neo4j. For the cluster-anchor primer, see What Is GraphRAG?.
The example you can run yourself
The five-minute proof is in recipe 016_graphrag_qna in the SynapCores Community Edition. It walks a small knowledge-graph traversal alongside a vector seed and shows the path-of-evidence the LLM uses to answer. Run it on the sample data, then point it at your own. If your data has real relationships you'll see the answer quality lift on the relational questions immediately. If your data is genuinely flat, you'll see why people stay on vector-only — and that's a useful signal too.
The honest version
We don't have customer logos yet. We're early. What I can tell you is the failure mode above — vector-only retrieval that can't follow edges — is the exact pain we built SynapCores to relieve. The Pinecone+Neo4j+LangChain stack works; the seams hurt; we built one engine.
If you're hitting the same wall, the Agent Memory JumpStart is a 2-4 week founder-led sprint where we wire SynapCores' graph + vector retrieval into your real workflow. Free Design Partner track for case studies; fixed-fee Paid Pilot from $5,000. Either way you talk to the engineer who built it — me.