The comparison in the title is one I've been asked maybe twenty times in the last six months, and the framing is wrong every time. GraphRAG and Neo4j aren't competitors. GraphRAG is a retrieval pattern — a way of combining vector similarity with graph traversal to feed better context into an LLM. Neo4j is a graph database — a piece of infrastructure where you store and query graphs. You can implement GraphRAG on Neo4j. You can also implement it on SynapCores, on Postgres+Apache AGE, on TigerGraph, or on a custom engine. The right question isn't "which one wins" — it's "for my workload, what's the right architecture?"
This post is that decision. I'll walk through what Neo4j is genuinely excellent at, what implementing GraphRAG on top of it looks like, where the dual-store sync cost (Neo4j + vector DB) starts to hurt, and when a unified engine is the better choice. The examples use SynapCores SQLv2 for the unified-engine side and Cypher for the Neo4j side. The conclusion isn't "pick SynapCores" — it's "pick the architecture that matches your operational appetite."
What Neo4j is
Neo4j is the dominant native graph database. It was the first commercially successful one, it invented or popularized Cypher (the graph query language that most other engines now speak), and it has fifteen-plus years of production deployments behind it. The data model is property graphs — typed nodes with properties, typed edges with properties — and the query language is among the most ergonomic any database has ever shipped.
What Neo4j does excellently:
- Native property-graph storage. Indexes on labels, properties, relationships. Designed for graphs, not retrofitted from rows.
- Cypher. The query language is genuinely good.
MATCH (a)-[r:KNOWS]->(b) WHERE a.name = 'Alice' RETURN bis the right level of abstraction. - Mature traversal performance. Multi-hop walks at millisecond latency on graphs of hundreds of millions of nodes.
- Production tooling. Clustering, backups, multi-tenancy, monitoring. The boring stuff is solved.
- The ecosystem. Graph data science library, visualization tools (Bloom, Neo4j Browser), integrations with everything.
What Neo4j doesn't do natively:
- Vector search. Neo4j added vector indexes in 5.11 (~2023). They work. They are not at parity with dedicated vector databases for high-recall workloads at scale. If your vectors are the primary access pattern, Neo4j's vector index is the secondary citizen of the engine.
- LLM integration. No
GENERATE()function inside Cypher. You call out to Python/LangChain. - Relational joins at scale. Neo4j is great at graph traversals; it's not optimized for "JOIN three tables on big indexed keys."
- AutoML or in-DB training. Out of scope.
This isn't a knock. Neo4j is a graph database. It does graphs. The tradeoff is that everything not graph (vectors, LLMs, ML training) lives somewhere else — and you become responsible for keeping those somewhere-elses in sync with Neo4j.
What GraphRAG is
GraphRAG is a retrieval pattern, not a piece of software. The pattern:
- Embed the user's question.
- Find the top-k chunks (or nodes) by vector similarity.
- Walk the graph N hops out from those seeds along typed edges.
- Feed the resulting subgraph (chunks + nodes + edges) into the LLM context.
You can read the long-form on this in What Is GraphRAG? and the cluster-comparison in GraphRAG vs Traditional RAG. The relevant point for this post: GraphRAG requires a vector index AND a graph engine. Two capabilities. How you provision them is the architectural decision.
Implementing GraphRAG on Neo4j (the multi-store path)
The most common architecture for GraphRAG on Neo4j is the dual-store pattern: Neo4j for the graph, a separate vector database (Pinecone, Chroma, Weaviate, pgvector) for the embeddings.
The flow:
User question
-> embed via OpenAI/sentence-transformers
-> top-k vector search in Pinecone
-> get node IDs back
-> Cypher query in Neo4j: MATCH (n) WHERE n.id IN [...] -[*1..2]- ()
-> assemble chunks + subgraph
-> stuff into LLM context
Code-wise (Python + LangChain-ish pseudocode):
# Step 1: vector search
seeds = pinecone.query(vector=embed(question), top_k=5)
seed_ids = [s['id'] for s in seeds]
# Step 2: graph traversal in Neo4j
cypher = """
MATCH (n:Chunk) WHERE n.id IN $ids
MATCH (n)-[r*1..2]-(m)
RETURN n, r, m
"""
subgraph = neo4j.run(cypher, ids=seed_ids)
# Step 3: feed to LLM
context = format_subgraph(subgraph)
response = openai.chat.completions.create(
messages=[{"role": "user", "content": question + "\n\nContext:\n" + context}]
)
This works. It's the canonical pattern, and there's nothing wrong with it on a small scale. Neo4j's vector index is also an option — keeps everything in one engine, gives up some vector-search performance, simplifies operations. Both are valid.
The cost shows up at scale. Specifically:
1. Two stores, one source of truth (sort of)
Every node in Neo4j has a corresponding vector in Pinecone. When the node's content changes, both stores need to update. The write path becomes:
def update_chunk(chunk_id, new_content):
new_emb = embed(new_content)
pinecone.upsert([(chunk_id, new_emb)])
neo4j.run("MATCH (n:Chunk {id: $id}) SET n.content = $c", id=chunk_id, c=new_content)
Two writes, no transaction across them. If the Pinecone write succeeds and the Neo4j write fails (or vice versa), you have drift. Every team I've seen running this pattern at scale has built some kind of reconciliation job — usually as a nightly cron — to scan for divergence. The reconciliation works. It's tax.
2. Two operational footprints
Neo4j has its own cluster topology, backup story, monitoring story, version cadence, IAM model. Pinecone (or your chosen vector DB) has another. Your on-call rotation now covers two clusters. Your DR plan covers two clusters. Your version bumps are coordinated.
3. The retrieval round-trip
The flow above does two network round-trips per query: app → Pinecone → app → Neo4j → app. At 10ms each, that's 20ms of pure overhead before the LLM is called. This is fixable with batching and connection pooling, but it's a real cost that disappears when both indexes share a process.
4. Schema divergence
This is the subtle one. Pinecone has a different notion of "filter" than Neo4j has of "property." When you want a hybrid query — "vectors close to X and nodes connected to Y" — the filtering happens in two places and the semantics don't always line up cleanly. The application becomes the merge layer, which means bugs live in the merge logic.
Implementing GraphRAG on a unified engine (the single-store path)
The alternative: an engine where the graph and the vector index share storage and the planner. SynapCores does this; so do a few other unified engines now. The same GraphRAG query becomes:
WITH seeds AS (
SELECT id FROM chunks
WHERE COSINE_SIMILARITY(embedding, EMBED(:question)) > 0.6
ORDER BY similarity DESC LIMIT 5
)
SELECT c.body, n.label, e.type, m.label, m.props
FROM seeds s
GRAPH MATCH (n:Chunk {id: s.id})-[e*1..2]-(m:Entity)
ORDER BY n.recency DESC LIMIT 20;
One query. One round-trip. One transaction. The planner picks the order — usually vector seed first, then graph expansion — and fuses the operations. No reconciliation job because there's nothing to reconcile.
The cost on this side is: the unified engine is younger than Neo4j, has a smaller ecosystem, and (if you've already invested in Neo4j operations) requires switching cost. We're being honest about this in Why Traditional Databases Fail Modern AI Workloads — the unified-engine argument is structural, not "Neo4j bad."
A decision matrix
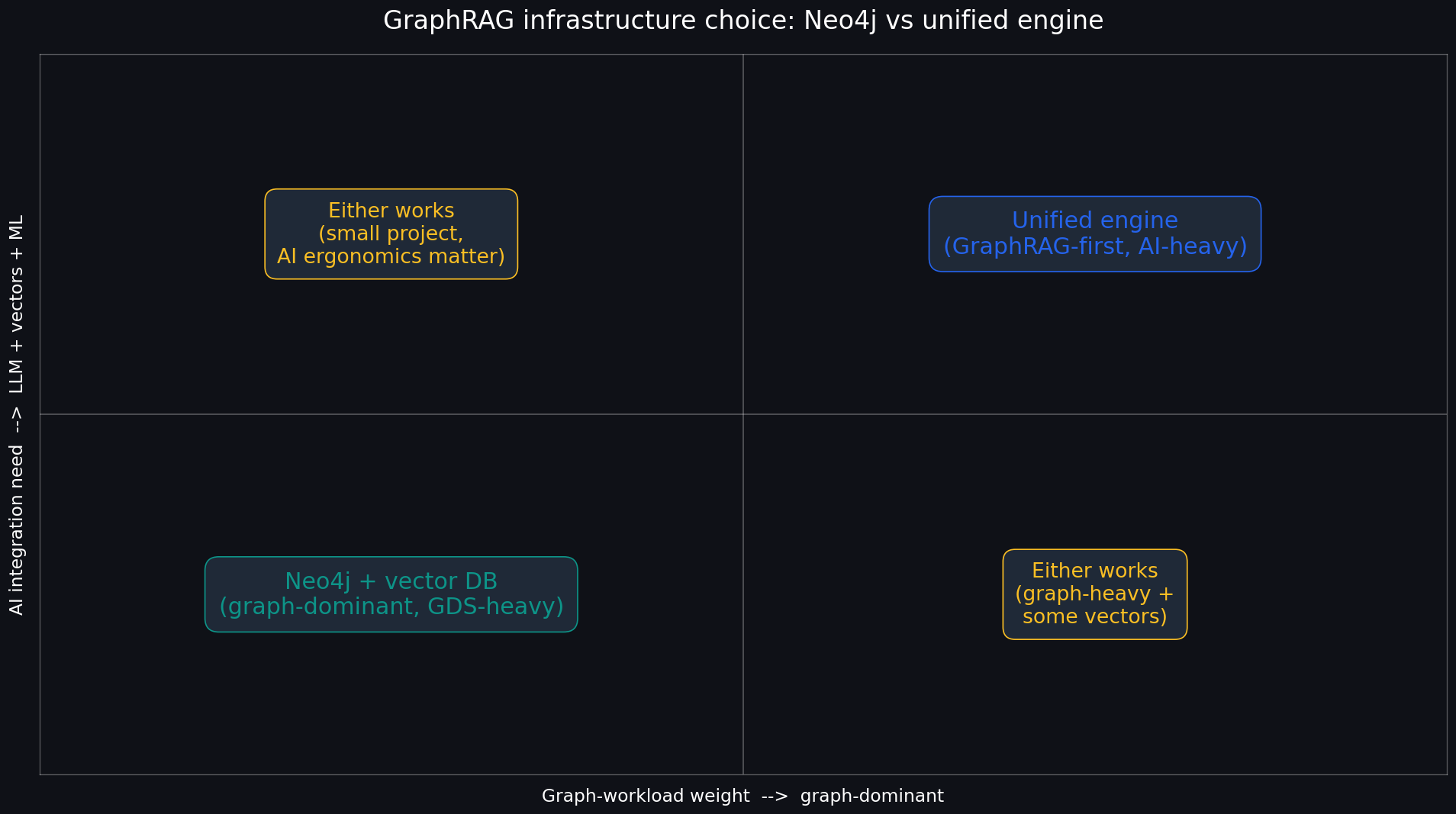
Real talk, here's how I actually advise teams:
| Signal | Choose Neo4j + vector DB | Choose unified engine |
|---|---|---|
| You're already deeply on Neo4j | Strong yes | Switching cost is real |
| Graphs are the dominant workload, vectors are a side feature | Yes — Neo4j is purpose-built | Unified engine is unnecessary |
| Vectors are dominant, graph is for occasional relationship queries | Dual-store sync is overkill | Yes — one engine is simpler |
| Both vector and graph are equally first-class | Sync cost real; pay it consciously | Yes — designed for this case |
| Greenfield project, no existing investment | Possible but operationally heavier | Yes — fewer moving parts on day one |
| You need mature graph data science library (PageRank at scale, community detection, etc.) | Yes — Neo4j ecosystem is unmatched here | Unified engines have less in this area |
You need GENERATE() and EMBED() callable from queries |
Need a Python layer | Native — see SQLv2 |
| Team has graph-DB ops experience | Strong yes | Either |
| Small team without graph-DB ops experience | Operational tax is high | Lower tax |
A summary: Neo4j is the right answer when graphs are the workload. A unified engine is the right answer when AI workloads (vectors + graphs + LLMs) are the workload and you'd rather not assemble five services.
Where Neo4j genuinely wins, in detail
I want to give Neo4j its due. There are workloads where it's the cleanest choice and where adding a unified engine to the comparison is silly.
- Pure graph workloads. Knowledge graphs in life sciences, social network analysis, supply chains. The vector dimension is incidental; the graph is the whole game.
- Graph data science. GDS library — community detection, centrality algorithms, link prediction, embeddings of graph nodes (Node2Vec, GraphSAGE). Mature, fast, well-supported.
- Cypher mastery on the team. If you have Cypher experts, leaning into Neo4j amortizes that expertise.
- The ecosystem. Bloom for visualization, integrations with every BI tool, a fifteen-year corpus of patterns and conference talks.
If those bullets describe your project, the dual-store sync cost is a price worth paying. The vector dimension is the secondary concern, not the primary.
Where a unified engine genuinely wins
The flip side. Where I'd default to a unified engine:
- Agent memory / GraphRAG as the primary product feature. Both layers (vectors and graph) are first-class. Sync is friction.
- You want LLM calls inside the query.
GENERATE()in SQL collapses three round-trips into one. - You want in-DB ML training.
CREATE MODEL+PREDICT()are first-class — see What Is In-Database Machine Learning?. - You don't have graph-DB ops budget. Running one engine is meaningfully cheaper than running two, especially at small team size.
- Latency budget is tight on relational queries. One round-trip vs two matters.
A worked migration scenario
Let's say you're already on Neo4j and you're evaluating whether to move to a unified engine. Here's the honest assessment:
- If your graph is well under 100M nodes and you have light vector volume: the unified engine usually pays back inside a quarter. The sync code you can delete is bigger than the migration cost.
- If your graph is large and graph-native (deep traversals, complex algorithms, GDS dependency): stay on Neo4j. Add a vector DB. The unified engine isn't worth the migration.
- If you're net-new and the requirements include both layers: start unified. Adopt Neo4j if and when the graph workload outgrows the unified engine.
The same advice in one line: migrate when the sync tax exceeds the migration cost. Don't migrate for ideology.
How GraphRAG-the-pattern translates between the two
Just to be concrete: the GraphRAG pattern itself is portable. You can implement it on either side. The architectural choice is about the operational shape of the implementation, not about whether GraphRAG is possible.
On Neo4j (dual-store):
seeds = vector_db.search(embed(q), k=5)
subgraph = neo4j.run("MATCH (n) WHERE n.id IN $ids MATCH (n)-[*1..2]-(m) RETURN ...", ids=[s.id for s in seeds])
answer = llm.complete(format(subgraph))
On a unified engine:
WITH seeds AS (
SELECT id FROM chunks
WHERE COSINE_SIMILARITY(embedding, EMBED(:q)) > 0.6
LIMIT 5
)
SELECT GENERATE('Answer using: ' || STRING_AGG(...))
FROM seeds s
GRAPH MATCH (Chunk {id: s.id})-[*1..2]-(m);
Same pattern. Different operational story.